GSoC 2025: Building Libretto, a Matrix Archiver
This post is also available on the MetaBrainz blog
Hello! I’m Jade Ellis, AKA JadedBlueEyes. You might know me from my project with MetaBrainz last year - if not, I’m happy to have the chance to introduce myself. I’m an undergraduate Computer Science student at the University of Kent in England, a music enthusiast and (in my spare time) a climber.
The Setting
In September 2024, MetaBrainz switched from IRC to Matrix as our primary form of communication. Matrix is a more feature-rich alternative to IRC, with capabilities like replies, edits, and reactions, while still being open source and aligning with the principles of our project.
When MetaBrainz primarily used IRC, we had a piece of software called BrainzBot. This was a multi-functional Python app that, most importantly, created a web-accessible archive of all messages in the MetaBrainz channels. Thanks to the bridges between IRC and Matrix, BrainzBot continued to trundle along, but it couldn’t understand modern features like edits, replies, or media. The code itself was also becoming decrepit—a fork of an abandoned project, showing its age.
This led to my GSoC project: to build a replacement for BrainzBot’s archival function - a chat archiver that natively understands and preserves Matrix’s rich features.
The Plan
Before writing any code, I had to work out what I was building and how I was building it. I talked with the team and wrote up a ‘pre-proposal’ - my ideas for what would be in scope for the project, features it would have, how certain features would work, and how it would be deployed. I got feedback, updated what was in scope, and iterated.
One of the hardest decisions to make was choosing the programming language. Originally, I defaulted to picking Rust. This was because it was the same language I used for last year’s project, and I knew it had the tools that were needed to complete the project. However, one of the MetaBrainz team members brought up that not everyone on the team knows Rust. That sparked a full investigation into both Rust and the alternatives. Ultimately, it came down to Rust or Python - the project was possible in both, and I even brought up a full project proposal for each of them.
Ultimately, I chose Rust. The full pros and cons of each choice are too long to write in this post, but the fact that ultimately tipped it over the edge was the ongoing, longtime investment in the Matrix Rust ecosystem, and the confidence that Rust as a language gives that a project will continue working along in the future. The latter is particularly important for an archival project that may not be touched for years at a time.
The rest of the design of the project involved finding and choosing the appropriate libraries from the ecosystem for features like templating, the web server, the matrix SDK, and possible search indexing.
We also identified particularly important features, like deciding on restoring the entire contents of the message history in the PostgreSQL database, rather than relying on the Matrix homeserver to stay up or writing HTML to disk exclusively.

Key goals
At the start of the project, this is what I wrote down:
Expected Outcomes:
- Matrix-native chat archiver, producing a portable, HTML-based output
- Support Matrix’s reply, redaction, and reaction features
- Support Matrix’s media features
Additional Objectives:
- Built-in full-text search functionality over past messages
- Full support for Matrix’s threaded conversations (initial support will fall back as replies, with a ‘thread’ marker)
Bonus:
- Write Maubot plugins to replicate functionality in BrainzBot that’s not already in Maubot plugins
The Results

I think it’s fair to say I hit the core objectives I set myself.
Right now you can visit libretto.ellis.link to see my demo instance. Right on the landing page you can see a list of all the rooms that are being archived. In the demo instance, it’s the main MetaBrainz rooms, the Libretto matrix room and a testing room, to show the more unusual Matrix features. It’s all themed in the MetaBrainz colours - under the hood, these are defined via CSS variables and can be swapped out for other branding.
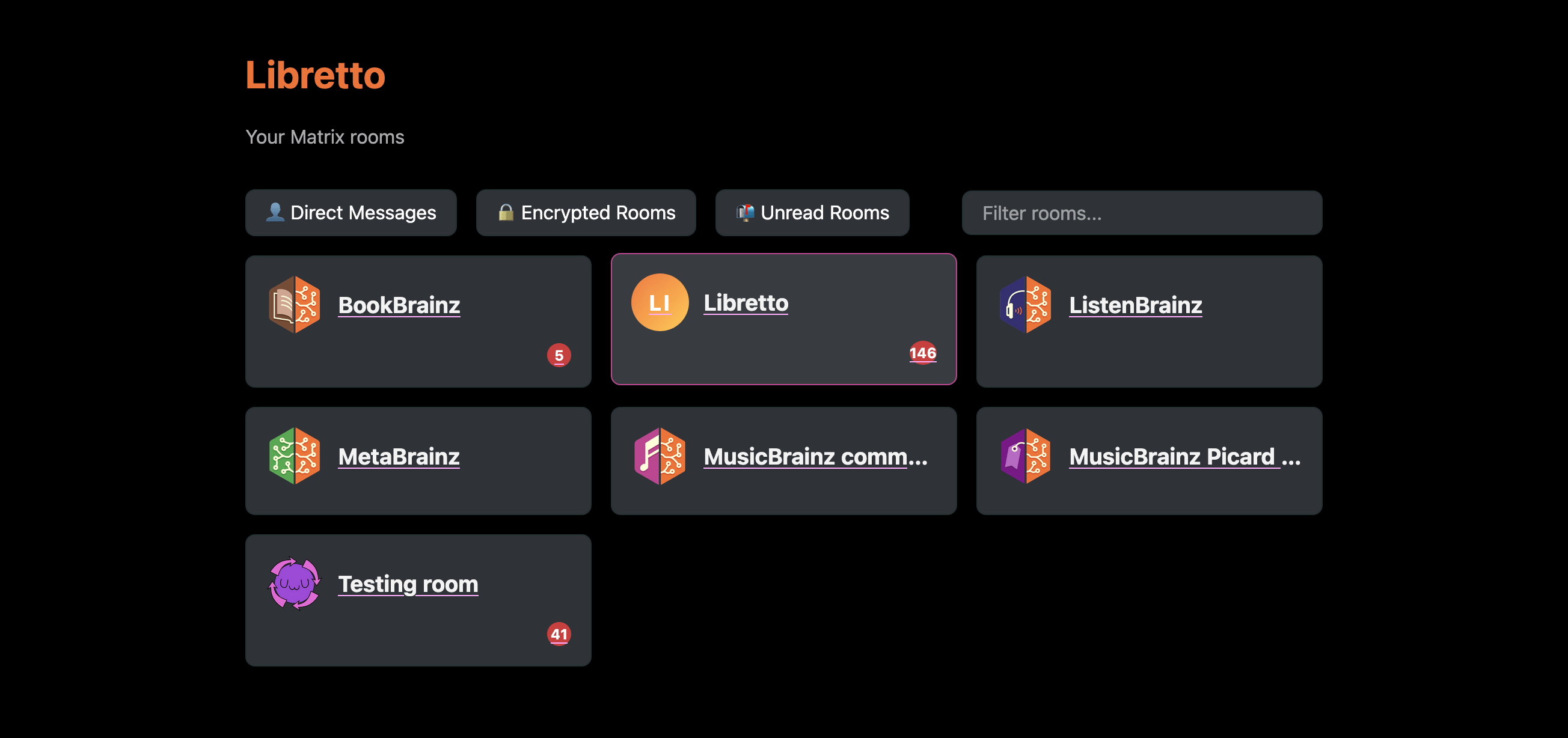
Once you click on a room, you can immediately see the message history. Everything is arranged in a readable format, avoiding repeated information whilst keeping everything in an information-rich layout. I’m using it in dark mode, but you can also view it in light mode.
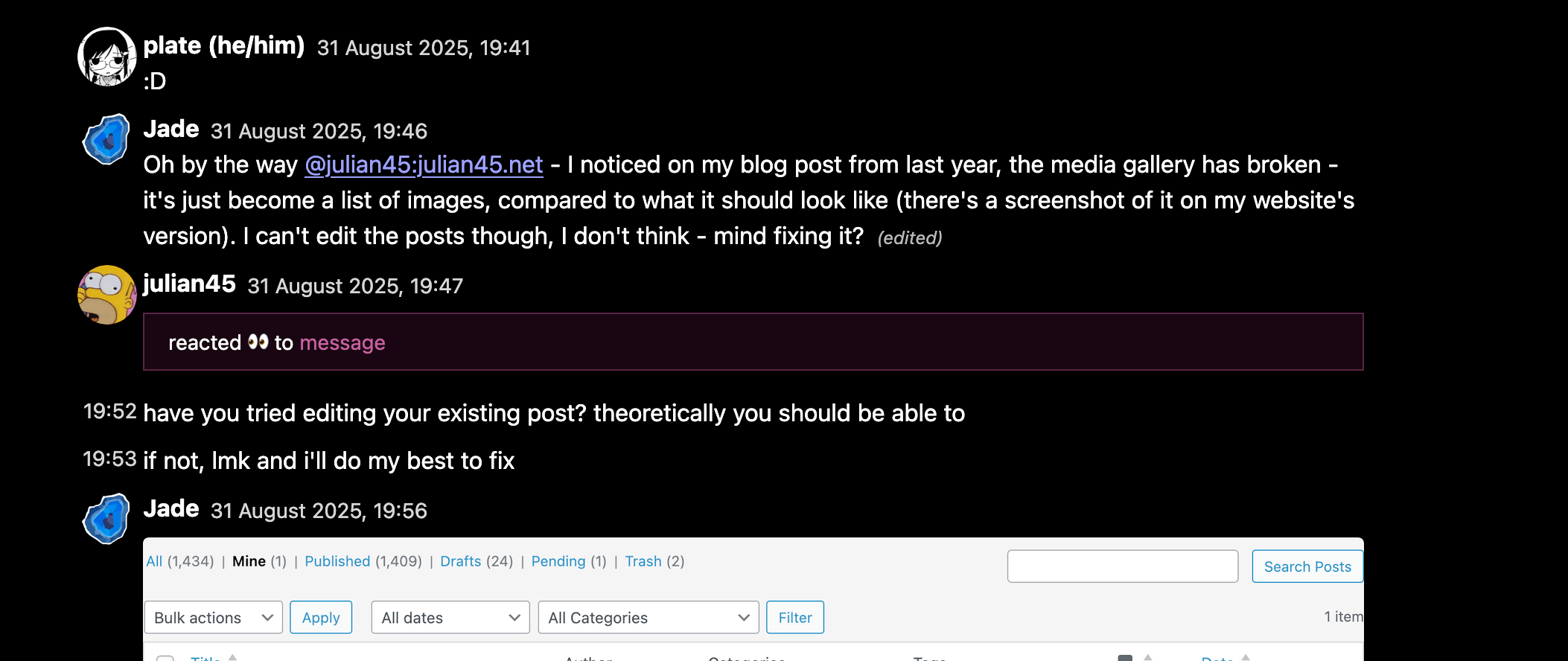
Edits, message deletion (redaction) and media work. But it’s not just that - matrix has many more obscure message types, too. Location messages, audio messages, joins, leaves, polls, files, calls, key verification, emotes, and more. Many of those can also contain important information like captions, that affect the contents of the conversation, and so I implemented at least basic support for as many as I reasonably could.
Behind the scenes, everything that the @libretto:ellis.link test account sees is getting recorded into a PostgreSQL database. When you go and fetch that page, a section of the timeline and some metadata about each person speaking in the room is retrieved. That data is then processed and fed into a template, which is what your browser sees. (If you’re wondering why the test instance takes half a sec to load, the database it’s running against is on the other side of the Atlantic!)

That database schema is non-trivial, too. One of the more interesting problems to implement was the timeline. There’s no way to sort events by themselves - the client must display them solely in the order that the server defines, and the server can give events in any order. To deal with that, the events and the order they appear in are stored in different tables. When a new event is received from the server, we add a new ID to the timeline greater than any previous. When we want to add history earlier than the first event we received, we add negative IDs to the timeline. Finally, when the server decides to reset the order that events appear, we can wipe out the timeline without deleting any of the events themselves - we just need to start fetching the order of the timeline again, in reverse chronological order.

On my personal testing instance, the event table has over 100,000 events, and that table by itself is over 130MiB. That’s a lot of talking!
The binary is set up to be easily deployed by Docker, too. Images are automatically published at ghcr.io/jadedblueeyes/libretto, so you just need to set up your account and your database.
There are some utility commands too - if you need to reset the synchronisation state or the timelines of the bot, that can be done from the command line.

I also got the bonus goal of writing the Maubot plugins done. The plugins were far simpler than the archiver itself!
When I was developing the Jira plugin, one bug managed to irritate me for a bit - after a while, requesting any data from Jira would start to fail. Mysteriously, restarting Maubot would fix the issue. It turns out that the HTTP library was saving cookies in memory, and Jira set a cookie that would become invalid after a set timeout, but wouldn’t expire. The fix was setting up a separate instance of the HTTP client with a special ‘never save any cookies’ jar.
What I learned
This project was a step up in complexity for me, compared to last year. There are lots of moving parts in this project, and they all need to come together to produce each feature. Even though I had expected a lot of complexity, more revealed itself as I implemented the archiver. That meant that features took longer than expected, and sometimes it felt like I was going backwards.
One example of this was the message profiles. I first implemented them near the start of the project, directly putting the data out of the SDK. However, when I refaced the project to make the web server poll data exclusively from the database, I no longer had access to the SDK method for membership profiles. That meant I had to deal with the underlying implementation of the feature in the protocol.
Rooms store metadata in hidden state – fed to the client separately from the timeline, but referring to events just the same – which had to be stored in the database to re-add the profiles. It was an unfortunate manifestation of the saying that a feature will always take twice the time you estimate to implement it – even when you take into account that it will take twice the amount of time. I’m lucky that I gave myself the flexibility for things to go wrong at the expense of additional features.
One of the other frustrations was managing new demands on my time compared to last year. A new open source project I was involved with starting, the Continuwuity Matrix homeserver, became a part of an ecosystem-wide coordinated security release. Issues surrounding that, and the wider Matrix ecosystem, took up a significant amount of time during the first half of the project that I hadn’t accounted for. Around the midpoint of the project, I figured out how to set boundaries and make sure I was prioritising the work that needed to get done, which helped me catch up on my timeline for Libretto.
My last regret with this project is that I picked something so different from the rest of the MetaBrainz project. That meant I wasn’t spending as much time talking with and working with the wonderful MetaBrainz team as I did last year - there were no APIs to integrate, just requirements to hammer out at the start and progress updates to give. It’s much more fun to work closely with other people than mostly by yourself.
These were super important lessons to learn, though – and the project helped me push myself even further than before. Learning to set my boundaries and focus on the work that needs to be done over a period is a super important skill. Once I had done that, I was able to complete features far faster than I initially expected at the start of the project. I’m also pleased that I managed to implement so much in 12 weeks, even when more complexity revealed itself.
What’s Next
While the core functionality is in place, there’s always more that can be done. Here are some of the features that didn’t make it in time for this post:
- Historic message backfill - the foundations are in place, but the logic to fetch a room’s full history from before the bot joined still needs to be implemented. This isn’t a light task - many rooms contain tens of thousands of messages, some even more!
- Currently, reactions are displayed as individual events. The next step is to group them under the message they are reacting to.
- The proposal included building a search index with Tantivy. This was an additional objective that I didn’t get to.
- A more special handling of threads is planned - you’ll be able to view each thread’s timeline, with only messages from that thread.
Of course, we also need to deploy Libretto on MetaBrainz’s servers to officially replace BrainzBot’s archiving duties.
Conclusion
GSoC 2025 has been an incredible journey again. I’m incredibly happy to have been given the opportunity once more, and I’m super pleased with the results so far. I’ve been able to build something useful, improve my software engineering skills and all the skills around that and deep dived into the Matrix protocol. I’m excited to see the project deployed, perhaps even outside of MetaBrainz!
A huge thank you to my mentor, julian45, and the entire MetaBrainz community for their guidance and support throughout the summer. It was a pleasure to work with you all again!
Oh, and one final bonus: A diagram showing how we process each event we receive from the server - excluding the processing the SDK does first.
